数据在各处被缓存
此图说明我们在典型架构中缓存数据的位置。
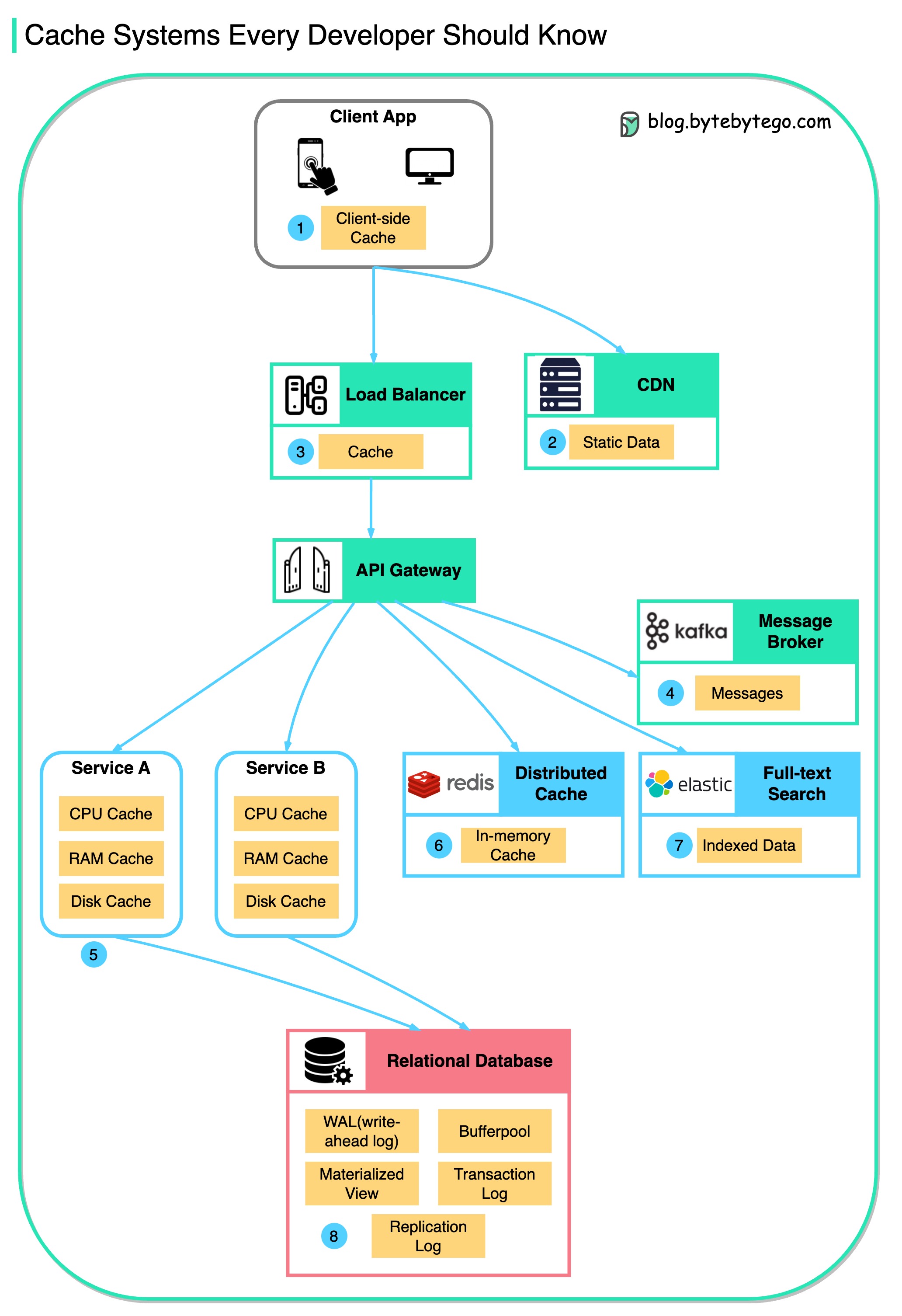
在此过程中存在多个缓存层级。
在整个流程中存在多个层次。
- 客户端应用:HTTP 响应可以被浏览器缓存。我们首次通过 HTTP 请求数据时,返回的数据在 HTTP 头中附带了过期策略;再次请求时,客户端应用会优先尝试从浏览器缓存中检索数据。
- CDN:CDN 缓存静态 web 资源。客户端可以从附近的 CDN 节点检索数据。
- 负载均衡器:负载均衡器也可以缓存资源。
- 消息基础设施:消息代理会先将消息存储在磁盘上,然后消费者可以根据需要进行检索。根据保留策略,数据会在 Kafka 集群中缓存一段时间。
- 服务:服务中存在多个层次的缓存。如果数据没有在 CPU 缓存中缓存,服务将尝试从内存中检索数据。有时服务会有二级缓存,将数据存储在磁盘上。
- 分布式缓存:像 Redis 这样的分布式缓存将多个服务的键值对保存在内存中。它提供比数据库更好的读写性能。
- 全文搜索:我们有时需要使用 ElasticSearch 等全文搜索引擎进行文档或日志的搜索。一份数据副本也会在搜索引擎中建立索引。
- 数据库:即使在数据库中,我们也有不同级别的缓存:
- WAL(预写日志):数据会先写入 WAL,然后再构建 B 树索引。
- 缓冲池:分配给缓存查询结果的内存区。
- 物化视图:预先计算查询结果并将其存储在数据库表中,以提升查询性能。
- 事务日志:记录所有事务和数据库更新。
- 复制日志:用于记录数据库集群中的复制状态。